李姐回收冬虫夏草东阿阿胶微信号《138,1133,7577》冬虫夏草 九朝贡胶 5X极草含片,近期东阿阿胶,老阿胶 回收冬虫夏草 qq 59,388,9206 高价收购同仁堂总统牌70克90克礼盒燕窝,各种5A???6A级散装马来西亚燕窝。毛燕、燕条、燕碎、泰国洞燕。同仁堂虫草22.5克25克40克60克80克120克,专业回收山东东阿阿胶、北京同仁堂阿胶、福牌阿胶,价格面议。

武汉市回收冬虫夏草《江汉 江岸 硚口 武昌区》价格高666

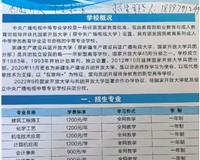
武汉市《这里》回收冬虫夏草《同仁堂或其他品牌》价格高V136·991·22221话同号[地址:本市范围内一律登门面议。价格:按产地、品牌、质量、规格、日期、数量以质论价,一般回收克价在88元至238元

武汉市回收冬虫夏草《徐家棚 汉正街 百花洲 黄鹤楼》价格高65

武汉市《这里》回收冬虫夏草《同仁堂或其他品牌》价格高V136·991·22221话同号[地址:本市范围内一律登门面议。价格:按产地、品牌、质量、规格、日期、数量以质论价,一般回收克价在88元至238元

武汉市《这里》回收冬虫夏草《同仁堂或其他品牌》价格高V136·991·22221话同号[地址:本市范围内一律登门面议。价格:按产地、品牌、质量、规格、日期、数量以质论价,一般回收克价在88元至238元

李姐回收冬虫夏草东阿阿胶微信号《13811337577》冬虫夏草 九朝贡胶 5X极草含片,近期东阿阿胶,老阿胶 回收冬虫夏草 qq 593889206 高价收购同仁堂总统牌70克90克礼盒燕窝,各种5A???6A级散装马来西亚燕窝。毛燕、燕条、燕碎、泰国洞燕。同仁堂虫草22.5克25克40克60克80克120克,专业回收山东东阿阿胶、北京同仁堂阿胶、福牌阿胶,价格面议。

武汉市《这里》回收冬虫夏草《同仁堂或其他品牌》价格高V136·991·22221话同号[地址:本市范围内一律登门面议。价格:按产地、品牌、质量、规格、日期、数量以质论价,一般回收克价在88元至238元

武汉市《这里》回收冬虫夏草《同仁堂或其他品牌》价格高V136·991·22221话同号[地址:本市范围内一律登门面议。价格:按产地、品牌、质量、规格、日期、数量以质论价,一般回收克价在88元至238元

武汉市回收冬虫夏草《江汉 江岸 硚口 武昌区》价格高76

武汉市《这里》回收冬虫夏草《同仁堂或其他品牌》价格高V136·991·22221话同号[地址:本市范围内一律登门面议。价格:按产地、品牌、质量、规格、日期、数量以质论价,一般回收克价在88元至238元

李姐回收冬虫夏草东阿阿胶微信号《138,1133,7577》冬虫夏草 九朝贡胶 5X极草含片,近期东阿阿胶,老阿胶 回收冬虫夏草 qq 59,388,9206 高价收购同仁堂总统牌70克90克礼盒燕窝,各种5A???6A级散装马来西亚燕窝。毛燕、燕条、燕碎、泰国洞燕。同仁堂虫草22.5克25克40克60克80克120克,专业回收山东东阿阿胶、北京同仁堂阿胶、福牌阿胶,价格面议。

位于黄武公路边,距离汉口北,金马凯旋家具城近,交通便利。整片硬化场地,可走打车,有护栏围挡,两个大门进出口。
品种: 哈士奇 年龄: 3个月 性别: 公母均有 价格: 1000 元/只 经营品种:哈士奇、泰迪、萨摩耶、比熊、金毛、拉布拉多、松狮、吉娃娃、博美、雪纳瑞、德国牧羊犬、贵宾、蝴蝶
武汉绿源丰物资回收公司市内任何地区均可上门收货,诚信交易,价格合理,中介定酬谢。欢迎来电,我们愿热忱地为您服务。 我司长期高价回收: 1.主机:各种型号、不同配置的电脑主机; 2.二手电脑:各种品牌(

武汉市《这里》回收冬虫夏草《同仁堂或其他品牌》价格高V136·991·22221话同号[地址:本市范围内一律登门面议。价格:按产地、品牌、质量、规格、日期、数量以质论价,一般回收克价在88元至238元
【公司介绍】 武汉管道疏通有限公司是一家管道清洗、下水道疏通、化粪池清洗、高压清洗、打捞物品为一体的管道服务公司。 【服务范围】 1、清掏:清理化粪池、隔油池、污泥池、下水井里油污杂物。 2、工业管道
专业日式烧肉、湘式烤肉。全国各地扶持开店、新店筹备,从选址到试营业一对一扶持、包括选址、设计装修、品牌策划、厨房设备、后厨菜品指导培训升级、餐具调料用品采购(也可提供进货渠道)。菜牌与价格定位,成本控
武汉降温冰块配送中心供应食用冰块批发出售配送,专注于食用冰块、降温大冰块、商场降温冰块、食用颗粒冰、食用方型冰块、奶茶食用冰块、酒吧食用冰块、透明冰块、展会冰块、小冰块、干冰、冰粒冰块等配送,正规厂家
服务项目: 传单派发、人气充场、礼仪模特、 展会兼职、展台搭建、安保服务、 提供各种临时工,兼职人员。 摄影摄像制作后期剪辑 可签合同 直投派发团队:派发范围:楼盘派单、展会派单、社区派发、写字楼派发

面授课程:HTML5大前端培训、JavaEE+分布式开发培训、Python全栈+人工智能培训、全链路UI/UE设计培训、云计算培训、全栈软件测试培训、大数据+人工智能培训、智能物联网+嵌入式培训、Un...
【机构介绍】 青鸟教育在数字艺术创意设计与教学方面已积累了丰富的经验和实力,现有专、兼职资深讲师15人,Adobe国际认证设计师6人、Autodesk国际认证三维动画工程师3人、Autodesk国际认...
面授课程:HTML5大前端培训、JavaEE+分布式开发培训、Python全栈+人工智能培训、全链路UI UE设计培训、云计算培训、全栈软件测试培训、大数据+人工智能培训、智能物联网+嵌入式培训、Un...
武汉学web前端全栈开发专业培训机构,web前端开发培训、JAVA培训、Python+人工智能培训、云计算大数据培训、软件测试培训、网络运维、网络安全培训等多种IT前沿技术培训课程。 学习方式: 线下...
1种,普通办公软件如office中常用的Word、Excel办公软件只需要学习1个月左右就可以了。 2种,office中的这些不常用的软件如果想要学会的。 3种,如果还要学习其他专业性的办公软件,如P...
本校面授课程:软件开发培训、HTML5大前端培训、JavaEE+分布式开发培训、Python全栈+人工智能培训、全链路UI或UE设计培训、云计算培训、全栈软件测试培训、大数据+人工智能培训、智能物联网...
去年就有研究人员发现了一种新的网络钓鱼活动,该活动利用二维码将受害者重定向到网络钓鱼登陆页面,有效规避了旨在阻止此类攻击的安全解决方案和控制措施。...
现在室内设计作为一个火热的行业,有很多的公司要求不但是一本学历证明,而更多的是倾向于工作经验。所以现在做室内设计的人,有些是草根出身,也有一些是从别的行业空降过来的,也就是俗话说的转行!特别是家庭...
天琥教育——全国连锁·互联网视觉教育专家!教学宗旨:把经验传递给有梦想的人教学口号:快学习,乐设计目前开设有UI设计、电商设计、平面设计、网页设计、室内设计等课程...
天琥教育提倡终身服务的理念,只要你是天琥学生...